
Chapter Nine Multiprocessors - PowerPoint PPT Presentation
Title:
Chapter Nine Multiprocessors
Description:
Programming models: Each processor has only local variables. ... Mesh, Tori , K-ary n-cube. Hypercube. Multi-stage networks (cross-bars and Omega networks) ... – PowerPoint PPT presentation
Number of Views:15
Avg rating:3.0/5.0
Title: Chapter Nine Multiprocessors
1
Chapter NineMultiprocessors
2
Multiprocessors
- Idea create powerful computers by connecting
many smaller ones good news works for
timesharing (better than supercomputer)
vector processing may be coming back bad news
its really hard to write good concurrent
programs many commercial failures
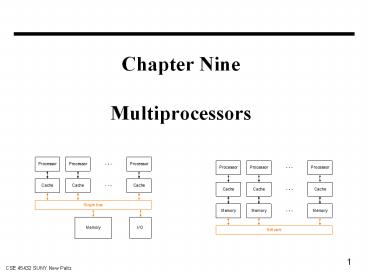
Shared Memory Multiprocessor or SMP - Symmetric
Multiprocessor
Distributed Memory Multiprocessor or Network
connected MP
3
Classification
- Shared address space -- Distributed address
space - Which memory locations can a processor access
from an instruction? - When a processor does not have access to the
entire memory in the system, information is
shared by message passing. - Uniform memory access, UMA -- Non-uniform memory
access, NUMA - Does the delay for accessing a memory location
depend on the address of that location? - UMA Shared memory multiprocessor or symmetric
multiprocessor - NUMA Distributed memory multiprocessor
- Parallel Processors -- Cluster of processors
- Speed of the interconnections (bus, switch,
network). - Single operating system or one OS for each
processor. - User writes many programs for the processors or
user writes one parallel program and a run-time
system (or parallel compiler) distributes the
work to the processors.
4
Parallel Programs
- Parallel programs need to
- Synchronize (locks, semaphores).
- Share data ( shared memory or send / receive
primitives). - Speedup, S(n) of an n processor system is the
time to execute on one processor divided by the
time to execute on n processors. - Linear speedup S(n) k X n
- Communication slows down the parallel system.
- Synchronization ( needed for data dependence)
also slows down the system. - Amdals law Parallel execution time the sum
of - Execution time for the parallel part n
- Execution time for the non-parallel part
5
Barrier Synchronization
- Example sum of A(i) for i 1, .. , 64 on 4
processors - Each processor computers the sum of 16 numbers.
- One processor computes the sum of 4 partial sums
- Parallel programs frequently need Barrier
Synchronization - When any processor reaches the barrier, it waits
until all processors reach that barrier, before
execution continues. - Processor 1
- Processor 2
- Processor 3
6
Cache Coherence in SMPs
- Different caches may
- contain different value for
- the same memory location
7
Snooping Cache Coherence Protocols
- Each processor monitors the activity on the bus
- On a read miss, all caches check to see if they
have a copy of the requested block. If yes, they
supply the data. - On the write miss, all caches check to see of
they have a copy of the requested data. If yes,
they either invalidate the local copy, or update
it with the new value. - Can have either write back or write through
policy.
8
Example
Write invalidate with write back
9
Example
Write update
10
Multiprocessors Connected by Networks
- May have only non-shared address spare -- that
is, each processor can access only local memory
and shared data is through message passing. - May have a global shared address space -- that
is, a processor can access any location in the
entire address space. Because some memory
accesses have to go through the network, the
machine is a NUMA. - Programming models
- Each processor has only local variables.
- Each processor ahs local variables but can also
access global variables shared by all processors. - Many network topologies can be sued to connect
the processor / memory pairs - Rings
- Mesh, Tori , K-ary n-cube
- Hypercube
- Multi-stage networks (cross-bars and Omega
networks).
11
Multiprocessors Connected as a Ring a Tree
12
Multiprocessors Connected as a hypercube
13
Multiprocessors Connected as a k-ary n-cube
14
Concluding Remarks
- Evolution vs. Revolution More often the
expense of innovation comes from being too
disruptive to computer users Acceptanc
e of hardware ideas requires acceptance by
software people therefore hardware people should
learn about software. And if software people
want good machines, they must learn more about
hardware to be able to communicate with and
thereby influence hardware engineers.
Recommended
CrystalGraphics Presentations





























