
Architectures de processeurs volus - PowerPoint PPT Presentation
1 / 28
Title:
Architectures de processeurs volus
Description:
0 0 0 0 0 1 0 1 0 0 1 0 1 0 0 1 0 0 0 0 0 0 0 0 0 1 1 1 1 0 0 1 ... translater. Principle validation with Shen algorithm. Processing functions on two processors ... – PowerPoint PPT presentation
Number of Views:34
Avg rating:3.0/5.0
Title: Architectures de processeurs volus
1
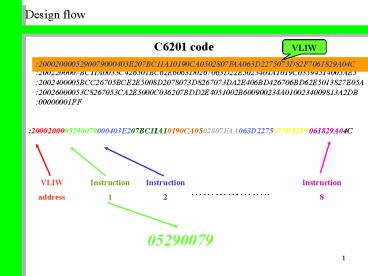
Design flow
C6201 code
VLIW
2000200005290079000403E207BC11A10190CA0502807FAA0
63D2275073D82F7061829A04C
2000200005290079000403E207BC11A10190CA0502807FAA0
63D2275073D82F7061829A04C
2002200007BC11A0033C426501BC62E6063D0267063D22E50
23401A1019C03594514005AE5 2002400005BCC26705BCE2E
5008D2078073D8267073DA2E406BD426706BD62E5013827E05
A 20026000053C8267053CA2E5000C036207BDD2E4051002B
600900234A0100234009813A2DB 00000001FF
2000200005290079000403E207BC11A10190CA0502807FAA0
63D2275073D82F7061829A04C
2000200005290079000403E207BC11A10190CA0502807FAA0
63D2275073D82F7061829A04C
2000200005290079000403E207BC11A10190CA0502807FAA0
63D2275073D82F7061829A04C
2000200005290079000403E207BC11A10190CA0502807FAA0
63D2275073D82F7061829A04C
2000200005290079000403E207BC11A10190CA0502807FAA0
63D2275073D82F7061829A04C
VLIW address
Instruction 1
Instruction 2
Instruction 8
..
05290079
1
2
Design flow
Instruction analysis example RA10 RA10 RA8
on L2
05290079 0 0 0 0 0 1 0 1 0 0 1 0
1 0 0 1 0 0 0 0 0 0 0 0 0 1 1 1 1 0 0 1
b31 b0
05290079 0 0 0 0 0 1 0 1 0 0 1 0
1 0 0 1 0 0 0 0 0 0 0 0 0 1 1 1 1 0 0 1
b31 b0
05290079 0 0 0 0 0 1 0 1 0 0 1 0
1 0 0 1 0 0 0 0 0 0 0 0 0 1 1 1 1 0 0 1
b31 b0
05290079 0 0 0 0 0 1 0 1 0 0 1 0
1 0 0 1 0 0 0 0 0 0 0 0 0 1 1 1 1 0 0 1
b31 b0
05290079 0 0 0 0 0 1 0 1 0 0 1 0
1 0 0 1 0 0 0 0 0 0 0 0 0 1 1 1 1 0 0 1
b31 b0
05290079 0 0 0 0 0 1 0 1 0 0 1 0
1 0 0 1 0 0 0 0 0 0 0 0 0 1 1 1 1 0 0 1
b31 b0
05290079 0 0 0 0 0 1 0 1 0 0 1
0 1 0 0 1 0 0 0 0 0 0 0 0 0 1 1 1 1 0 0
1
b0 parallel bit
b23 -gt b27 destination register (RA10)
b1 -gt b4 unit used
b5 -gt b11 operation type
b13 -gt b17 first operand register (RA8)
b18 -gt b22 second operand register (RA10)
2
3
Design flow
Harware set analysis result
Registers
Calculating units (CU)
Operations for each unit
Register in for each unit
Register out for each unit
Other elements
3
4
Design flow
Source writing in C or C6201 assembler
Automatic processor VHDL model generation
Automatic hardware characteristics extraction
Soft fonctionnel simulation
Synthesis Routing
Hardware Database
C6201 Code
FPGA bistream
4
5
Design flow
VHDL model generation 3 kind of data
Analysis data
Configuration data
DSP
RA0
RB3
Peripheral 1
Constant data
RA1
RB7
Peripheral 2
RA5
State registers
L1
L2
Memory managing
D1
D2
PC
M1
5
6
Design flow
Génération automatique
5 inputs max
32 inputs max
L1
Addition
RA0
Subtraction
RA1
Absolute V.
RA5
D2
RB3
RB7
6
7
Design flow
An example
Sobel filter
- Assembler source in TI library
- CCS (Code Composer Studio) simulation
- Analysis and model generation
- VHDL model test whith Modelsim
- Test on Virtex II board
7
8
Design flow
RA3
RA9
RA10
Addition
RA12
RA13
Subtraction
RA5
RA8
RA14
Absolute V.
RB3
RB10
8
RB11
9
Design flow
L1
RB1
L1
RA2
S1
9
10
Design flow
For Sobel filter
- 30 registers on 32 ( 90)
- 14 operations on 186 ( 8)
- 37 input connections on 384 ( 10 )
- 36 output connections on 160 ( 22 )
1610 slices on synthesis (15 on VirtexII 2000)
10
11
Plan
- Target processor choice
- The design flow proposed
- Experimental validations
- Experimental validations
- SynDEx interface
- Conclusion and perspectives
11
12
Experimental validations
We use the multimédia board
Vidéo Codecs
FPGA Virtex II - 2000
UART
5 external memories
12
13
Experimental validations
Test plateform architecture
video
video
Input Codec
Acquisition
RAM ZBT
Restitution
OutputCodec
DMA channels
DSP C6201 model
Picoblaze
13
Serial link
14
Experimental validations
Neural network recognition
Extraction (4032 pixels)
Filter
Pre-processing
Distance calculating
(9,6 µs)
(3,2 µs)
- 40 of registers
- 10 of operations
- 9,3 of input connections
- 11 of output connections
25 of slices (5 Picoblaze and other)
14
multi-processors application possible
15
Experimental validations
Vidéo
Vidéo
Input Codec
Acquisition
RAM ZBT
Restitution
OutputCodec
DMA channels
DSP C6201
DSP 1
DSP 2
DSP 3
DSP 4
- - Pré-processing
- Distance calculating with
- 3 hidden neural
Picoblaze
Distance calculating with 4 hidden neural
Serial link
15
16
Experimental validations
multi-processors synthesis results
A full DSP uses 14361 slices (134 of virtex
II-2000)
7,8 images /seconde (100 MHz )
16
17
Experimental validations
Design flow tests with curent algorithms
Multi-processor application possible
Important simplification factor
17
18
Experimental validations
Multi-processors application
Need for tools to place and shedule tasks on the
different processors
18
19
Plan
- Target processor choice
- The design flow proposed
- Experimental validations
- SynDEx interface
- SynDEx interface
- Conclusion and perspectives
19
20
SynDEx
- SynDEx made
- Architecture Algorytm Adequacy (AAA)
Algorithm
Architecture
P1
P2
T1
T2
T3
P3
T4
T5
Adequacy
P1
P2
T1
T5
T3
P3
T2
T4
20
21
SynDEx
- Used for simulation
Generate a lot of files
- Architecture description (processors number,
communication link)
- Processors pseudo-code
SynDEx provides code generation tools for some
target processors
21
22
SynDEx
SynDEx-IC SynDEx circuit extension proposed by
A²SI laboratory
SynDEx-IC
(source présentation Thierry GRANDPIERRE /
ESIEE-A²SI)
Design flow
VHDL
SynDEx
Goal to etablish a bridge between SynDEx and
the design flow
22
23
SynDEx
Algorithm decomposition in processing functions
Architecture specification
Software graph
Processing code
Hardware graph
Functions time
Simulator Compiler
SynDEx
SynDEx
Functions dispatching
DSP code
Communication managing
Functions scheduling
Générateur VHDL dUnités de Contrôle
Control units VHDL Generator
Générateur VHDL des DSPs
DSP VHDL Generator
VHDL files Fusion
23
24
SynDEx
SynDEx macro-code Picoblaze translater
SynDEx processor model
Calculating scheduler
Communication scheduler
T1
Communications
T2
Synchronization
T3
Processor architecture
UC
UT
ROM
ROM
Picoblaze communications
Picoblaze processing
DMA channel
DMA channel
Privated Ram
24
25
SynDEx
- Principle validation with Shen algorithm
Processing functions on two processors
Communication with BLOCRAM
VHDL realization 6 slices on Virtex 2-2000
25
26
Plan
- Target processor choice
- The design flow proposed
- Experimental validations
- SynDEx interface
- Conclusion and perspectives
- Conclusion and perspectives
26
27
Conclusion
Fast prototyping FPGA development for the non
electronic experts
Adapted processor ASIP automatic generation
(Application Specific Instruction
Processor)
Co-design possibilities mixing with existing
tools (scilab/scicos)
Multi-processors applications optimised with
SynDEx interface
28
Perspectives
- SynDEx interface
- Picoblaze -gt DSP in the UT
- Files fusion realization
- Optimize the VHDL model
- more multi-processor with simplified VHDL model
Recommended
CrystalGraphics Presentations





























