
65 Synchronization with semaphores - PowerPoint PPT Presentation
1 / 11
Title:
65 Synchronization with semaphores
Description:
Operations: accessSem(SEM) and release(Sem) Synchronize Code with binary ... (They could be connected to the Embedded Nios II-pro-cessor with the Avalon bus) ... – PowerPoint PPT presentation
Number of Views:26
Avg rating:3.0/5.0
Title: 65 Synchronization with semaphores
1
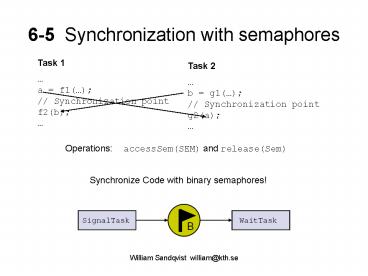
6-5 Synchronization with semaphores
Task 1 a f1()// Synchronization
pointf2(b)
Task 2 b g1()// Synchronization
pointg2(a)
Operations accessSem(SEM) and release(Sem)
Synchronize Code with binary semaphores!
2
Binary semaphores Sem1 and Sem2
Task 1 accessSem(Sem1)a
f1()releaseSem(Sem1)// Synchronization point
accessSem(Sem2)f2(b)releaseSem(Sem2)
Task 2 accessSem(Sem2)b
g1()releaseSem(Sem2)// Synchronization point
accessSem(Sem1)g2(a) releaseSem(sem1)
3
7-1 Hardware Accelerators
DSP application. 15 of the execution time are
calls to a function that performs a MAC
operation. Multiply and ACkumulate. An
alternative is to use an other processor which
has a MAC-instruction. Suppose that we have the
ratio
How much could the total execution time be
increased if the processor with the
MAC-instruction is used?
Without MAC 15 85 100 With MAC
1.5 85 13.5 100 a program could do
13.5 moore in the same execution time.
4
7-3 Hardware accelerator
X A B C D
5
Processor only
X A B C D
load p1,A 2 time units load p2,B
2load p3,C 2load p4,D 2mul p5,p1,p2
8mul p6,p3,p4 8add p7,p5,p6 1store p7,X
2Grand total 27 time units
Can the Hardware Accelerator improve on this?
6
Processor and Accelerator
TCDXABT
load p1,A 2 load p2,B 2mul p3,p1,p2
8 load a1,C 2 load a2,D
2 mul a3,a1,a2 1
store T,a3 2 (7) load p4,T
2add p5,p4,p3 1store p5,X 2Grand total
17 time units
Parallellism!
7
All muls with the accelerator
load a1,A 2
load a2,B 2 load
a3,C 2 load a4,D 2
mul a5,a1,a2 1
mul a6,a3,a4 1 store S,a5
2 store T,a6 2load
p1,S 2 load p2,T 2add p3,p2,p1
1store p3,X 2 Grand total 21
SABTCDXST
No parallellism!
8
Accelerators in the Cyclone II chip
The Cyclone II chip has Embedded Multipliers to
use as Hardware accelerators. (They could be
connected to the Embedded Nios II-pro-cessor with
the Avalon bus).
Up to 150 18bit?18bit Multiplicator units can be
used!
9
5-9 Cache performance
This is a example of a problem from part B of the
written exam.
int iint y 0int u60int v60. .
.for(i 0 i lt 60 i) y ui vi. .
.
Datacache size 128 Bytes, Cacheline/Block 32
Bytes (8 int).u and v are located in sequence in
memory. Variables i and y are stored in
processor registers.
10
Hitrate estimation
Draw the memory and Cache as Cache-line/Block
organized. Block is then 8 int. Vector u and v
each occupy 7.5 blocks in memory. We dont know
if the mapping looks exactly this way, but the
conflicts will be the same. u0 M, v0 M,
u13 HHH, v13 HHHu4 H, v4 M, conflict
misses u57 MMM, v57 MMM MM HHH HHH H M
MMM MMM 50 (loop stops at 59, numbers 6063
are not included, the hitrate will actually be gt
50)
11
Program changes for max hitrate
int iint y 0int u72 / 12 dummy /
int v60. . .for(i 0 i lt 60 i) y
ui vi. . .
v is moved 12 ints by extending u with dummy
elements. MHHHHHHH.Hitrate 88. Is 100
possible?
No, there must always be one cold miss every
cacheline. The index i counts forwards every
int is used only once, no int is reused!
Recommended
CrystalGraphics Presentations





























