
Objective - PowerPoint PPT Presentation
Title:
Objective
Description:
3. Use the Postal Code and City and State name/abbreviations later in the recognition ... of the address block components: City/State name, Postal Code, Country name ... – PowerPoint PPT presentation
Number of Views:47
Avg rating:3.0/5.0
Title: Objective
1
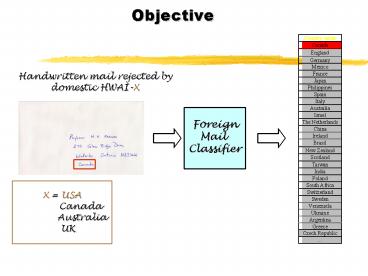
Objective
Handwritten mail rejected by domestic HWAI-X
Foreign Mail Classifier
X USA Canada
Australia UK
2
Algorithm
3
1
2
Steps 1. Consider only the last three lines of
the mail address for processing 2. Consider the
one-word hypothesis as a possible location of
the country name 3. Use the Postal Code and City
and State name/abbreviations later in the
recognition process to validate/enforce the
country name recognition
3
Obtain word hypotheses
Address
Word hypotheses
Line separation
Parsing
...
4
Algorithm
5
Naïve Bayes Classifier
- Want to classify a new instance (a1, a2,, an)
into finite number of categories (targets) from a
set V. - Bayesian approach
- assign the most probable category vMAP given (a1,
a2,, an). - Can we estimate the probabilities from the
training data?
6
Naïve Bayes Classifier
- Second probability easy to estimate
- estimated by the frequency of each target value
in the training data - The first probability difficult to estimate
- cannot use frequency for argmax P(a1,a2,,anv)
unless we have a very large set of training data
to get a reliable estimate - Assume independence (this is the naïve bit)
- P(aiv) can be estimated by frequency or by
m-estimate
7
Foreign Mail Recognition
- Question How to use Naïve Bayes Classifier for
Handwritten Foreign Country Name Recognition? - Set of targets V Albania, Afghanistan,,Zambia
. - Which attributes to choose?
- Address features (of lines,of words/line,etc)
- Postal Code estimated location in the address
block - Postal code format obtained from parsing
(ddddd,ddttdd,etc) - First/Last letter in the Country name(e.g France
F or P - Bigrams,Trigrams frequency
- Structural features (average character height,
characters aspect ratio) - Low-level features( of holes,sphericity,etc -
helpful for language identification) - Relative order of the address elements in the
mail address
8
Learn Probabilities
- For all countries vj in V
- mailsV total number of mail pieces in the
Training set - mailsvj subset of mail pieces from the Training
set with the destination country vj - mailsFRANCE mail pieces from the Training set
with the destination country France - Calculate P(vj)
- P(FRANCE) mailsFRANCE/mailsV
- Calculate P(dddddvj) using the m-estimate
method - P(dddddFRANCE) (ncmp)/(nm), where
- p 1/k, where k of different Postal Code
formats - n mailsFRANCE
- n of samples from the mailsFRANCE set that
have the PC format ddddd - m total of country destinations
9
Classification
10
Naïve Bayes Classifier for Foreign Mail
Classification
- Training Set 1450 mail pieces
- 119 different country destinations
- we have 20 mail pieces/country for most countries
- some countries have less than 20 entries
- Test Set 500 mail pieces
- Preliminary Set of Features used
- Number of Lines in the Mail Piece
- Number of components - First Line
- Number of Components - Second Line
- Number of Components - Third Line
- First Letter on the Last Line
- Last Letter on the Last Line
- Length of the word on the Last Line
11
Naïve Bayes Classifier for Foreign Mail
Classification
- Sample Vectors
- For South Africa
- POR02174 REPUBLICOFSOUTHAFRICA 7 9 4 10 S A
11 - POR02533 REPUBLICOFSOUTHAFRICA 5 8 15 12 S A
11 - POR02958 REPUBLICOFSOUTHAFRICA 7 4 6 11 R A
21 - POR02965 REPUBLICOFSOUTHAFRICA 7 4 9 11 S A
11 - For Australia
- POR16191 AUSTRALIA 6 2 2 2 E I 5
- POR16240 AUSTRALIA 5 7 8 8 T A 7
- POR16257 AUSTRALIA 5 3 4 4 N S 11
- POR16417 AUSTRALIA 6 4 3 4 A A 9
- POR16534 AUSTRALIA 5 5 8 8 A A 9
12
Naïve Bayes Classifier for Foreign Mail
Classification
- Compute P(vj) and P(aivj) for each country
destination from the Training Set - Example
- Australia
- P(Australia) 20/1450
- P(NoLines 5Australia) (101)/(208)
- P(NoComps on Line 1 13Australia) (51)/(20
31) - P(FirstLetterAAustralia) (111)/(2025)
- P(LastLetter ZAustralia) (01)/(2020)
- P(LastLineLength 9Australia) (131)/(2018)
13
Naïve Bayes Classifier for Foreign Mail
Classification
- Classify the vectors from the Test Set
- Example Vector for unknown country
- PRT26371 UNKNOWN DESTINATION 5 1 6 3 T A 7
- P(Destination Australia) P(NrLines5Australia
) P(No.Components on Line 1 13Australia) .
P(LastLineLength 7Australia) - P(Destination Zimbabwe) .
14
Naïve Bayes Classifier for Foreign Mail
Classification
15
Naïve Bayes Classifier for Foreign Mail
Classification
- Errors
- Confusion
- Detected Dest. AUSTRALIA ( 9 1 0 3 7 10 7)
Actual Dest. ARGENTINA ( 5 5 14
11 A A 9) - Detected Dest. CROATIA ( 6 0 1 1 9 9 0)
Actual Dest. ITALY ( 4 4
6 4 C A 14) - Few samples for a country
- CROATIA ( 5 3 1 1 1 9 8)
ETHOPIA ( 5 10 9 9 E A 7)
16
Naïve Bayes Classifier for Foreign Mail
Classification
- Total Set of 10330 mail pieces
- Divided into three sets Training,Validation,Test
- Training Set 2681 mail pieces
- 119 different country destinations, all
represented - one third of the samples for each country are
included - Test Set 2435 mail pieces
- randomly chosen
17
Cleaning the Data
- Problem
- The features extracted have to be reliable
- Some features are inherently reliable
- Number of Lines,Number of Components on different
lines - Other features depend on the recognizers
performance - First/Last Letter in the Country name,Length of
the word,etc - Make sure that we get accurate data
18
Cleaning the Data
- Problems
- Wrong country assigned in the truth file
- Missing country name
19
Cleaning the Data
- Country name on a different line
- Country name together with some other information
- Country name with noise
20
Cleaning the Data
- Feature Length of the country name
- important to be accurately estimated
- Use several recognizers to converge to the right
result - Pre-recognition parser -gt Estimate1
- If word is cursive, use a word recognizer
-gtEstimate 2 - If word is not cursive, use a character
recognizer -gt Estimate 3
21
Naïve Bayes Classifier for Foreign Mail
Classification
22
Structural Features
- Features to investigate
- Relative order of the address elements in the
address - PostCode length/format
- Gap(s) in the last line
- indicates that a country name is composed of two
words
23
Structural Features
- Structural feature
- Is there a Gap in the country name?
- Problems
- The results from the parser are not always
reliable
- The best segmentation is not always the one
expected
24
Structural Features
- Word practically unbreakable
- Extra noise makes word unbreakable
- We have to be careful not to break valid words
25
Structural Features
- Feature Relative order of the address block
components City/State name, Postal Code, Country
name - Problems
- We dont have all the elements present. When we
have them, we cannot always recognize them
- For certain countries this feature is not
reliable
26
Naïve Bayes Classifier for Foreign Mail
Classification
27
Structural Features
- Next
- Features
- PostCode length/format
- Confidences values for individual characters
- Design a module to recognize first and last
character only
28
Features
- Noise
- Pre-recognizer classifies components in
OTHERSTUFF and FRAGMENT when it decides that they
are most probably not LETTERS or DIGITS - 1 - if the level of noise is above a certain
threshold, 0 otherwise
29
Features
- Different Alphabet
- Images of Letters/Digits in the Roman alphabet
have an average number of horizontal/vertical
transitions WHITE-gtBLACK - Characters in other alphabets present a
different average
30
Features
- PC Length and Line Position
31
Features
- Continent Id
32
Naïve Bayes Classifier for Foreign Mail
Classification
- F7 - noise
- F8 - different alphabet
- F9 - Gap in country name
- F10 - PC length
- F11 - PC line
- F12 -Continent Id
- Features
- F1 - no. of lines
- F2 - no. of components Line 1
- F3 - no. of components Line 2
- F4 - no of components Line 3
- F5 - First Letter Country Name
- F6 - Last Letter Country Name
Recommended
CrystalGraphics Presentations





























