
Instruction-Level Parallelism - PowerPoint PPT Presentation
Title:
Instruction-Level Parallelism
Description:
Instruction-Level Parallelism Review of Pipelining (the laundry analogy) Instruction-Level Parallelism Review of Pipelining (Appendix A) Instruction-Level Parallelism ... – PowerPoint PPT presentation
Number of Views:442
Avg rating:3.0/5.0
Title: Instruction-Level Parallelism
1
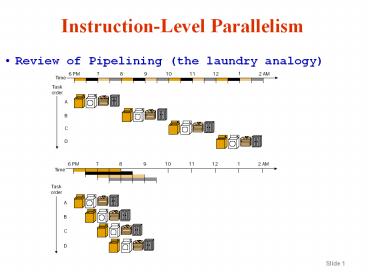
Instruction-Level Parallelism
- Review of Pipelining (the laundry analogy)
2
Instruction-Level Parallelism
- Review of Pipelining (Appendix A)
3
Instruction-Level Parallelism
- Review of Pipelining (Appendix A)
- MIPS pipeline five stages
- IF instruction fetch
- ID instruction decoding and operands fetch
- EX execution using ALU, including effective
address and target address computing - MEM accessing memory for L S instructions
- WB write result back to (destination) register
4
- The naïve MIPS pipeline
5
Instruction-Level Parallelism
- The naïve MIPS pipeline -- implementation
6
Instruction-Level Parallelism
- A series of datapaths shifted in time
7
Instruction-Level Parallelism
- A pipeline showing the pipeline registers between
stages
8
The major hurdles of pipelining pipeline hazards
- Structural Hazards resource conflicts, such as
bus, register file ports, memory ports, etc.
9
The major hurdles of pipelining pipeline hazards
- Data Hazards data dependency (producer-consumer
relationship, or read after write). Some can be
resolved by forwarding
10
The major hurdles of pipelining pipeline hazards
- Data Hazards data hazards detection in MIPS
pipeline
11
The major hurdles of pipelining pipeline hazards
- Data Hazards the logic for forwarding of data in
MIPS pipeline
12
The major hurdles of pipelining pipeline hazards
- Data Hazards the forwarding of data in MIPS
pipeline
13
The major hurdles of pipelining pipeline hazards
- Data Hazards Some cannot be resolved by
forwarding, thus requiring stalls
14
The major hurdles of pipelining pipeline hazards
- Data Hazards Avoid non-forwardable data hazards
through compiler scheduling
15
The major hurdles of pipelining pipeline hazards
- Branch (Control) Hazards can cause greater
performance loss (e.g., a 3-cycle loss in the
naïve MIPS pipeline)
16
The major hurdles of pipelining pipeline hazards
- Branch (Control) Hazards improved MIPS pipelined
with one-cycle loss
17
The major hurdles of pipelining pipeline hazards
- Reducing branch penalties
- Freeze or Flussh
- Predict-not-taken or Predict-taken
- Delayed Branch
- Branch instruction
- Sequential successor
- Branch target if taken
- Canceling/nullifying
- Branch if prediction
- incorrect
18
The major hurdles of pipelining pipeline hazards
- Scheduling the branch delay slot
19
Performance of Pipelining
- Example 1
- Consider an unpipelined machine A and a pipelined
machine B where CCTA 10ns, CPI(A)ALU CPI(A)Br
4, CPI(A)l/s 5, CCTB 11ns. Assuming an
instruction mix of 40 for ALU, 20 for branches,
and 40 for l/s, what is the speedup of B over A
under ideal conditions?
20
Performance of Pipelining
- Impacts of pipeline hazards
21
Performance of Pipelining
- Performance of branch schemes
- Overall costs of a variety of branch schemes
with the MIPS pipeline
22
Performance of Pipelining
- Example 2 For a deeper pipeline such as that in
a MIPS R4000, it takes three pipeline stages
before the target-address is known and an
additional stage before the condition is
evaluated. This leads to the branch penalties for
the three simplest branch schemes listed below - Find the effective addition to the CPI arising
from branches for this pipeline, assuming that
unconditional, untaken conditional, and taken
conditional branches account for 4, 6, and 10,
respectively. - Answer
23
What Makes Pipelining Hard to Implement?
- Exceptional conditions (e.g., interrupts, etc)
often change the order of instruction execution
24
What Makes Pipelining Hard to Implement?
- Actions needed for different types of exceptional
conditions
25
What Makes Pipelining Hard to Implement?
- Stopping and Restarting Execution Two Challenges
26
What Makes Pipelining Hard to Implement?
- Stopping and Restarting Execution Two Challenges
(contd)
27
What Makes Pipelining Hard to Implement?
- Precise Exception Handling in MIPS
Pipeline Stage Problem exceptions occurring
IF Page fault on instruction fetch misaligned memory access memory protection violation
ID Undefined or illegal opcode
EX Arithmetic exception
MEM Page fault on data fetch misaligned memory access memory-protection violation
WB None
28
What Makes Pipelining Hard to Implement?
- Precise Exception Handling in MIPS
29
Extending MIPS Pipeline to Handle Multicycle
Operations
- Handle floating point operations single cycle
(CPI1) ? very long CCT or highly complex logic
circuit - Multiple cycle ?long latency with EX cycle
repeated many times and/or with multiple PF
function units - The MIPS pipeline with three additional
unpipelined, floating point units
30
Extending MIPS Pipeline to Handle Multicycle
Operations
- Pipelining FP functional units
- Latency number of intervening cycles between the
producer and the consumer of an operand -- 0 for
ALU and 1 for LW - Initiation interval number of minimum cycles
between two issues of instructions using the same
functional unit.
F. Unit Int. ALU Data Mem FP Add Multiply Divide
Latency 0 1 3 6 24
Init. Interval 1 1 1 1 25
31
Extending MIPS Pipeline to Handle Multicycle
Operations
- Pipeline timing of a set of independent FP
instructions - A typical FP code sequence showing the stalls
arising from RAW hazards - Three instructions want to perform a write back
to the FP register simultaneously
MUL.D IF ID M1 M2 M3 M4 M5 M6 M7 MEM WB
ADD.D IF ID A1 A2 A3 A4 MEM WB
L.D IF ID EX MEM WB
S.D IF ID EX MEM WB
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
L.D. F4,0(R2) IF ID EX MM WB
MUL.D F0,F4,F6 IF ID Stall M1 M2 M3 M4 M5 M6 M7 MM WB
ADD.D F2,F0,F8 IF Stl ID Stl Stl Stl Stl Stl Stl A1 A2 A3 A4 MM WB
S.D. F2,0(R2) IF Stl Stl Stl Stl Stl Stl ID EX Stl Stl Stl MM
1 2 3 4 5 6 7 8 9 10 11
MUL.D F0, F4, F6 IF ID M1 M2 M3 M4 M5 M6 M7 MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
ADD.D F2, F4, F6 IF ID A1 A2 A3 A4 MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
L.D. F2, 0(R2) IF ID EX MEM WB
32
Extending MIPS Pipeline to Handle Multicycle
Operations
- Difficulties in exploiting ILP various hazards
that impose dependency among instructions, as a
result - RAW(read after write) j tries to read a source
before i writes to it - WAW(write after write) j tries to write an
operand before it is written by i - WAR(write after read) j tries to write a
destination before it is read by - Implementing pipeline in FP hazards and
forwarding in longer latency pipelines - Divide not fully pipelined (structural hazard)
- Multiple writes in a cycle and arrive at WB
variably,WAW and structural hazards. Would there
be WAR? - Out-of-order completion of instructions ? more
problems for exception handling - Higher RAW frequency and longer stalls due to
longer latency
33
Extending MIPS Pipeline to Handle Multicycle
Operations
- Introduce interlock
- tracking the use of write port at ID and stalling
issue if detected - use shift register for tracking issued
instructions' use of write port - stall when entering MEM
- can stall any of the contending instructions,
- no need to detect conflict early when is it
harder to see, - give priority to the unit with the longest
latency, - can cause bottleneck stalling
- WAW occurs if LD is issued one cycle earlier and
has F2 as destination (WAW with ADDD) Solution - delay issuing LD until ADDD enters MEM, or,
- stamp out result of ADD
- Hazard detection with FP pipeline
- check for structural hazards a. functional
units, b. write ports - check for RAW hazard source reg. in ID dest.
reg. (issued) - check for WAW hazard dest reg. in ID dest.
reg. (issued)
34
Extending MIPS Pipeline to Handle Multicycle
Operations
- Maintain precise exception
- Example of out-of-order completion
- DIVF F0, F2, F3 exception of
SUBF at end of ADDF - ADDF F10, F10, F8 cause imprecise
exception which - SUBF F12, F12, F14 cannot be solved
by HW/SW - Solutions
- Fast imprecise (tolerable in 60's 70s, but much
less so now due to pipelined FP, virtual memory,
and IEEE standard) or slow precise - Buffering of result until all predecessors
finish - the bigger the difference among instruction
execution lengths, the more expensive to
implement (e.g., large number of comparators and
MUXs and large amount of buffer space) - history file keeps track of register values
- future file keeps newer values of registers
until all predecessors are completed - Quasi-precise exception keep enough information
for trap-handling routine to create a precise
sequence for exception - operations in the pipeline and their PCs
- software finishes all instructions issued prior
to the latest completed instruction - Guarded issuing issue only if it is certain that
all prior instructions will complete without
causing an exception - stalling to maintain precise exception
35
The MIPS R4000 Pipeline
- R4000 pipeline leads to a 2-cycle load delay
36
The MIPS R4000 Pipeline
- R4000 pipeline leads to a 3-cycle basic branch
delay since the condition evaluation is performed
during the EX stage
37
Dynamic Scheduling with Scoreboard
- Dynamic Scheduling hardware re-arranges the
instruction execution order to reduce stalls - handles situations where dependences are unknown
or difficult to detect at compile time, thus
simplifying the compiler design - increases portability of the compiled code
- solves problems associated with the so-called
head-of-the-queue (HOTQ) blocking caused by
in-order issue of earlier pipelines. Example - MIPS, which is in-order issue, can be made to
out-of-order execute (implying out-of-order
completion) by splitting ID into two phases (1)
In-order Issue check for structural hazards. (2)
Read operands wait until no data hazards, then
read operands (and then execute, possibly
out-of-order!). The HOTQ problem above can be
solved in this new MIPS!
38
Dynamic Scheduling with Scoreboard
39
Dynamic Scheduling with Scoreboard
40
Dynamic Scheduling with Scoreboard
41
Dynamic Scheduling with Scoreboard
42
Dynamic Scheduling with Scoreboard
43
Dynamic Scheduling with Scoreboard
44
Dynamic Scheduling with Scoreboard
45
Unpipelined Processor (MIPS)
46
Pipelined Processor (MIPS)
47
The Eight-stage Pipeline of the R4000
48
A 2-cycle Load Delay of The R4000 Integer Pipeline
Recommended
CrystalGraphics Presentations





























