
AMP: Program Context Specific Buffer Caching - PowerPoint PPT Presentation
1 / 1
Title:
AMP: Program Context Specific Buffer Caching
Description:
The most used eviction policies, LRU and variants, perform very badly for large loops and scans ... Li: list of previously accessed blocks, ordered from oldest ... – PowerPoint PPT presentation
Number of Views:21
Avg rating:3.0/5.0
Title: AMP: Program Context Specific Buffer Caching
1
AMP Program Context Specific Buffer Caching
Feng Zhou, Rob von Behren, Eric Brewer,
zf,jrvb,brewer_at_cs.berkeley.edu, University of
California, Berkeley
http//www.cs.berkeley.edu/zf/amp
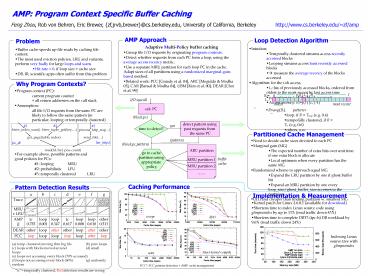
AMP Approach
Loop Detection Algorithm
Problem
- Adaptive Multi-Policy buffer caching
- Group file I/O requests by originating program
contexts. - Detect whether requests from each PC form a loop,
using the average access recency metric. - Use a separate MRU partition for each loop PC in
the cache. Adapt sizes of all partitions using a
randomized marginal-gain-based method. - Related work PCC Gniady et al. 04, ARC
Megiddo Modha 03, CAR Bansal Modha 04,
UBM Kim et al. 00, DEAR Choi et al. 99
- Intuition
- Temporally clustered streams access recently
accessed blocks - Looping streams access least recently accessed
blocks - ? measure the average recency of the blocks
accessed - Algorithm for the i-th access,
- Li list of previously accessed blocks, ordered
from oldest to the most recent by last access
time - pi position in Li of the block accessed
- Access recency Ripi/(Li-1)
- Buffer cache speeds up file reads by caching file
content - The most used eviction policies, LRU and
variants, perform very badly for large loops and
scans - Hit rate 0, if loop size gt cache size
- DB, IR, scientific apps often suffer from this
problem
Why Program Contexts?
- Program context (PC)
- current program counter all return addresses
on the call stack - Assumption
- all file I/O requests from the same PC are likely
to follow the same pattern (in particular,
looping or temporally clustered)
I/O syscall
calc PC
- Ravg(Ri). pattern
- loop, if R lt Tloop (e.g. 0.4)
- temporally clustered, if R gt Ttc (e.g. 0.6)
- others, o.w.
(block,pc)
time to detect?
detect pattern using past requests from the
same PC
yes
Partitioned Cache Management
(pattern)
- Need to decide cache sizes devoted to each PC
- Marginal gain (MG)
- The expected number of extra hits over unit time
if one extra block is allocate - Local optimum when every partition has the same
MG - Randomized scheme to approach equal MG
- Expand the LRU partition by one if ghost buffer
hit - Expand an MRU partition by one every
loop_size/ghost_buffer_size accesses to the
partition - O(1) and cheaper than finding partition w.
smallest MG
(block,pc,pattern)
ARC partition
go to cache partition using appropriate policy
- For example above, possible patterns and good
policies for PCs - 1 looping MRU
- 2 probabilistic LFU
- 3 temporally clustered LRU
MRU partition 1
buffercache
MRU partition 2
Caching Performance
Pattern Detection Results
Implementation Measurement
- Kernel patch for Linux 2.6.8.1 (available for
download) - Shortens time to index Linux source code using
glimpseindex by up to 13 (read traffic down 43) - Shortens time to complete DBT3 (tpc-h) DB
workload by 9.6 (read traffic down 24)
cscope
dbt3
Indexing Linux source tree with glimpseindex
(a) temp. clustered moving thru big file (b)
pure loops (c) loops with blocks moved around
(d) small loops (e) loops not accessing every
block (70 accessed) (f) loops not accessing
every block (60) (g) uniformly
random tctemporally clustered, Red detection
results are wrong
linux-kernel-compile
scan
PCC PCC pattern detection AMP cache management
Recommended
CrystalGraphics Presentations





























