
Stalling - PowerPoint PPT Presentation
Title:
Stalling
Description:
Stalling – PowerPoint PPT presentation
Number of Views:35
Avg rating:3.0/5.0
Title: Stalling
1
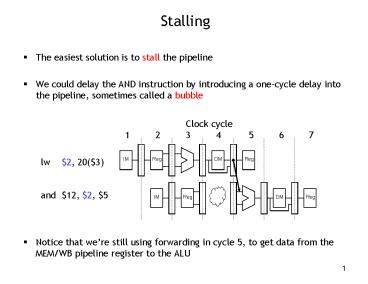
Stalling
- The easiest solution is to stall the pipeline
- We could delay the AND instruction by introducing
a one-cycle delay into the pipeline, sometimes
called a bubble - Notice that were still using forwarding in cycle
5, to get data from the MEM/WB pipeline register
to the ALU
Clock cycle 1 2 3 4 5 6 7
lw 2, 20(3) and 12, 2, 5
DM
Reg
Reg
IM
1
2
Stalling and forwarding
- Without forwarding, wed have to stall for two
cycles to wait for the LW instructions writeback
stage - In general, you can always stall to avoid
hazardsbut dependencies are very common in real
code, and stalling often can reduce performance
by a significant amount
Clock cycle 1 2 3 4 5 6 7 8
lw 2, 20(3) and 12, 2, 5
DM
Reg
Reg
IM
2
3
Load-Use Hazard Detection
- Check when using instruction is decoded in ID
stage - ALU operand register numbers in ID stage are
given by - IF/ID.RegisterRs, IF/ID.RegisterRt
- Load-use hazard when
- ID/EX.MemRead and ((ID/EX.RegisterRt
IF/ID.RegisterRs) or (ID/EX.RegisterRt
IF/ID.RegisterRt)) - If detected, stall and insert bubble
4
How to Stall the Pipeline
- Force control values in ID/EX registerto 0
- EX, MEM and WB do nop (no-operation)
- Prevent update of PC and IF/ID register
- Using instruction is decoded again
- Following instruction is fetched again
- 1-cycle stall allows MEM to read data for lw
- Can subsequently forward to EX stage
5
Stalling delays the entire pipeline
- If we delay the second instruction, well have to
delay the third one too - This is necessary to make forwarding work between
AND and OR - It also prevents problems such as two
instructions trying to write to the same register
in the same cycle
Clock cycle 1 2 3 4 5 6 7 8
lw 2, 20(3) and 12, 2, 5 or 13, 12, 2
DM
Reg
Reg
IM
DM
Reg
Reg
IM
5
6
What about EX, MEM, WB
- But what about the ALU during cycle 4, the data
memory in cycle 5, and the register file write in
cycle 6? - Those units arent used in those cycles because
of the stall, so we can set the EX, MEM and WB
control signals to all 0s.
Clock cycle 1 2 3 4 5 6 7 8
lw 2, 20(3) and 12, 2, 5 or 13, 12, 2
Reg
Reg
IM
DM
Reg
IM
DM
Reg
Reg
IM
6
7
Detecting Stalls, cont.
- When should stalls be detected?
- EX stage (of the instruction causing the stall)
lw 2, 20(3) and 12, 2, 5
mem\wb
ex/mem
id/ex
if/id
mem\wb
Reg
Reg
IM
DM
Reg
id/ex
ex/mem
if/id
if/id
- What is the stall condition?
- if (ID/EX.MemRead 1 and (ID/EX.rt IF/ID.rs
or ID/EX.rt IF/ID.rt)) - then stall
7
8
Adding hazard detection to the CPU
8
9
Stalls and Performance
- Stalls reduce performance
- But are required to get correct results
- Compiler can arrange code to avoid hazards and
stalls - Requires knowledge of the pipeline structure
10
Code Scheduling to Avoid Stalls
- Reorder code to avoid use of load result in the
next instruction - Ex c code for A B E C B F
lw t1, 0(t0) lw t2, 4(t0) add t3, t1,
t2 sw t3, 12(t0) lw t4, 8(t0) add t5, t1,
t4 sw t5, 16(t0)
lw t1, 0(t0) lw t2, 4(t0) lw t4,
8(t0) add t3, t1, t2 sw t3, 12(t0) add t5,
t1, t4 sw t5, 16(t0)
stall
stall
11 cycles
13 cycles
11
Branches in the original pipelined datapath
When are they resolved?
ID/EX
EX/MEM
WB
PCSrc
MEM/WB
M
Control
WB
IF/ID
EX
M
WB
4
P C
Shift left 2
RegWrite
Read register 1
Read data 1
MemWrite
ALU
Read address
Instruction 31-0
Zero
Read register 2
Read data 2
0 1
Address
Result
Write register
Data memory
Instruction memory
MemToReg
ALUOp
Registers
Write data
Write data
Read data
ALUSrc
1 0
Sign extend
Instr 15 - 0
RegDst
MemRead
Instr 20 - 16
Instr 15 - 11
11
12
Branch Hazards
- If branch outcome determined in MEM
Flush theseinstructions (Set controlvalues to 0)
PC
13
Reducing Branch Delay
- Move hardware to determine outcome to ID stage
- Target address adder
- Register comparator
- Example branch taken
- 36 sub 10, 4, 840 beq 1, 3, 744
and 12, 2, 548 or 13, 2, 652 add
14, 4, 256 slt 15, 6, 7 ...72
lw 4, 50(7)
14
Example Branch Taken
15
Example Branch Taken
16
Data Hazards for Branches
- If a comparison register is a destination of 2nd
or 3rd preceding ALU instruction
add 1, 2, 3
add 4, 5, 6
beq 1, 4, target
Can resolve using forwarding
17
Data Hazards for Branches
- If a comparison register is a destination of
preceding ALU instruction or 2nd preceding load
instruction - Need 1 stall cycle
lw 1, addr
add 4, 5, 6
IF
ID
beq stalled
ID
EX
MEM
WB
beq 1, 4, target
18
Data Hazards for Branches
- If a comparison register is a destination of
immediately preceding load instruction - Need 2 stall cycles
lw 1, addr
IF
ID
beq stalled
ID
beq stalled
ID
EX
MEM
WB
beq 1, 0, target
19
Branch Prediction
- Longer pipelines cant readily determine branch
outcome early - Stall penalty becomes unacceptable
- Predict (i.e., guess) outcome of branch
- Only stall if prediction is wrong
- Simplest prediction strategy
- predict branches not taken
- Works well for loops if the loop tests are done
at the start. - Fetch instruction after branch, with no delay
20
Dynamic Branch Prediction
- In deeper and superscalar pipelines, branch
penalty is more significant - Use dynamic prediction
- Branch prediction buffer (aka branch history
table) - Indexed by recent branch instruction addresses
- Stores outcome (taken/not taken)
- To execute a branch
- Check table, expect the same outcome
- Start fetching from fall-through or target
- If wrong, flush pipeline and flip prediction
21
1-Bit Predictor Shortcoming
- Inner loop branches mispredicted twice!
outer inner beq ,
, inner beq , , outer
- Mispredict as taken on last iteration of inner
loop - Then mispredict as not taken on first iteration
of inner loop next time around
22
2-Bit Predictor
- Only change prediction on two successive
mispredictions
23
Calculating the Branch Target
- Even with predictor, still need to calculate the
target address - 1-cycle penalty for a taken branch
- Branch target buffer
- Cache of target addresses
- Indexed by PC when instruction fetched
- If hit and instruction is branch predicted taken,
can fetch target immediately
24
Concluding Remarks
- ISA influences design of datapath and control
- Datapath and control influence design of ISA
- Pipelining improves instruction throughputusing
parallelism - More instructions completed per second
- Latency for each instruction not reduced
- Hazards structural, data, control
- Main additions in hardware
- forwarding unit
- hazard detection and stalling
- branch predictor
- branch target table