
QUESTION - PowerPoint PPT Presentation
Title:
QUESTION
Description:
For the following sequence of memory references, show the ... [SH-DRT] There are multiple shared caches copies. This is the last one being updated (Ownership) ... – PowerPoint PPT presentation
Number of Views:61
Avg rating:3.0/5.0
Title: QUESTION
1
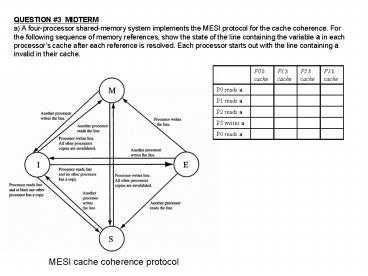
QUESTION 3 MIDTERM a) A four-processor
shared-memory system implements the MESI protocol
for the cache coherence. For the following
sequence of memory references, show the state of
the line containing the variable a in each
processors cache after each reference is
resolved. Each processor starts out with the line
containing a invalid in their cache.
MESI cache coherence protocol
2
Initial assumption a invalid in all caches
P0 reads a
3
P1 reads a
P2 reads a
4
P3 writes a
1. P0 reads a
5
2. P3 writes back a
3. P0 reads a
6
QUESTION 3 MIDTERM b) Consider a
multiprocessing system with 8 processors that
have their local caches and they are connected to
the main memory If Full Map Directory cache
coherence protocol is implemented, what is the
number of bits per directory? Why? 1 bit is used
per processor, so that the number of bits is
8 If Limited Directory cache coherence protocol
with only two pointers is implemented, what is
the number of bits per directory? Why? Log283,
the number of bits per pointer is 3 and the total
number of bits is 6 Assume that Full Map
Directory cache coherence protocol with
Centralized Directory Invalidate is implemented.
Assume that directory for address X contained all
0s at the beginning. Fill the following table for
the following sequence of instructions
7
ASSIGNMENT 3 1) Count the number of
transactions on the bus for the following
sequence of activities involving shared data.
Assume that both processors use write-back
write-update cache coherency, and a block size of
one word. Assume that all the words in both
caches are clean.
Initial assumption there are multiple cache
copies shared
8
Write-update / write-back states
9
100
104
100
104
104
100
10
(No Transcript)
11
ASSIGNMENT 3 2) Two processors require access
to the same line of data from data memory.
Processors have a cache and use the MESI
protocol. Initially both caches are
empty. Figure bellow depicts the consequence of
a read of line x by Processor P1. If this is the
start of a sequence of accesses, draw the
subsequent figures for the following
sequence 1. P2 reads x 2. P1 writes to x 3. P1
writes to x 4. P2 reads x
P1 reads x
12
P2 reads x
P1 writes to x
P1 writes to x
1. P2 reads x
2. P1 writes back x
3. P2 reads x
13
Write-Through Cache State Transitions
ASSIGNMENT 3 3a) Is the simplest possible cache
coherence protocol. It requires that all
processors use a write-through policy. If a write
is made to a location cached in remote caches,
then the copies of the line in remote caches are
invalidated. ? easy to implement but requires
more bus and memory traffic because of the
write-through policy
R Read, W Write, Z Replacei local
processor, j other processor
14
ASSIGNMENT 3 3b) Makes a distinction between
shared and exclusive states. When a cache first
loads a line, it puts it in the shared state. If
the line is already in the modified state in
another cache, that cache must block the read
until the line is updated back to main memory,
similar to the MESI protocol. The difference
between the two is that the shared state is split
into the shared and exclusive states for MESI
? reduces the number of write- invalidate
operations on the bus
15
- QUIZ 3
- QUESTION 2
- What is the diameter of
- A hypercube with 256 processors? 8
- A 2D mesh with 64 processors? 14
- A linear array with 32 processors? 31
- A star network with 17 processors (1 in the
middle and 16 leaf processors)? 2 - A 2D torus with p processors (assume that routing
is bidirectional) 2 - What is the bisection width of
- A hypercube with 256 processors? 128
- A 2d mesh with 64 processors? 8
- A linear array with 32 processors? 1
- A star network with 17 processors (1 in the
middle and 16 leaf processors)? 8
16
- QUESTION 3
- b) Modify this program in order to compute
cumulative sums C. Cumulative sum C is an array
of n - elements which are computed as C(i)Z(1)Z(2)Z(i
). - Write a program for parallel computation of
cumulative sums on M processors. Input array is Z
and it
17
- INITIALIZE //assign proc_nums and M where M is
the number of processors - read_array(Z, n) //read the array and array
size n from file - BARRIER(M) //waits for M processors to get to
this point in the program - local_sum 0 size_to_sum n/M
- lower_ind size_to_sum proc_num
- upper_ind size_to_sum (proc_num 1)
- for (i lower_ind i lt upper_ind i)
- Ci0
- Ci Ci-1Zi
- BARRIER(M) //waits for M processors to get to
this point in the program - for (jM-1jgt1j--)
- if (proc_numgtj)
- for (i lower_ind i lt upper_ind i)
- Ci CiCsize_to_sum j
- BARRIER (M)
Recommended
CrystalGraphics Presentations





























